Historically, when I wanted to send some part on my home traffic from my non-primary IP address, I’d use VPN. My whole NAS’s subnet was pretty much routed through wireguard at all times. Now that my new NAS is kubernetes-first, I re-evaluate some of those decisions and make things better. In this post I will explain how I managed to send only some of the pods’ traffic over VPN.
Now, there are many solutions to this problem, one of the most prominent of which is gluetun, a docker container sidecar that does VPN. I very much don’t like the idea of individual pods setting up VPN connections, though, because the traffic goes dark in my netflow that I collect from my RouterOS setup. Luckily, it’s not too hard to have RouterOS do the routing decisions for kubernetes!
How would a router outside of the kubernetes network control plane know if the traffic should be routed over a VPN or directly? The obvious answer to that is by source IP. Of course, all kubernetes CNIs masquerade pod traffic from the node addresses (because that’s the reasonable thing to do, by default). Some, however, allow to disable that. Few support several IP allocation pools. Cilium does both.
For my cilium’s values.yaml I run with the following:
|
|
These settings tell cilium to first, do not make any address translation for egress traffic, second, do not do any routing decisions for it, and finally, to allocate the pod IPs from the multi pool IPAM. Effectively, that means that cilium maintains several IP pools and will allocate the addresses based on pod annotations. In my case I have a default pool:
|
|
that allocates the IPv4 addresses further NAT-ed by the router, and publicly routable IPv6 addresses, and a vpn pool:
|
|
that allocates IPv4 addresses from a different subnet, and private IPv6 addresses. Note that while it’s possible to allocate the IPv6 addresses from fe80::/10, this setup will be effectively breaking IPv6 traffic in-cluster, because cross-pod communication is never link-local. For me it broke the cilium ingress. I don’t need IPv6 addresses on the pods that go through the VPN, but pods can’t have an option of having a single-stack address in a dual-stack cluster, so I have to provide some IP there.
The rest is easy, slap an ipam.cilium.io/ip-pool: vpn annotation on the pods you need and they will get their IP addresses that look like 10.20.1.123.
No networking works now, of course, because the packets will leave k8s nodes with the source IP addresses of the pods, so the router must know to masquerade them for egress and it needs the routes to send them back. First, the outgoing NAT:
/ip firewall nat
add action=src-nat chain=srcnat out-interface=wan \
src-address=10.20.0.0/24 to-addresses=198.51.100.23
add action=src-nat chain=srcnat out-interface=vpn \
src-address=10.20.1.0/24 to-addresses=10.2.0.2
Simple enough, the traffic that leaves out of the wan interface is SNATed to my public IP, the traffic that goes out to vpn is SNATed to the VPN interface’s address. How would the router know where to send the traffic? Easy, we just mark it:
/routing table
add disabled=no fib name=vpn
/ip route
add disabled=no distance=1 dst-address=0.0.0.0/0 \
gateway=vpn pref-src=0.0.0.0 routing-table=vpn scope=30 \
suppress-hw-offload=no target-scope=10
/ip firewall mangle
add action=mark-routing chain=prerouting dst-address-list=!LAN \
new-routing-mark=vpn passthrough=yes src-address=10.20.1.0/24
We add a new routing table called vpn, then add a default gateway that points at the vpn interface in it, and, finally, add a mangle rule that marks all the packets from 10.20.1.0/24 to use the new routing table (unless they happen to target one of the other LANs, for which we still use the main routing table).
With this, the pod packets will leave the node, then head for the public internet. There’s a bit of an issue on the way back, though.
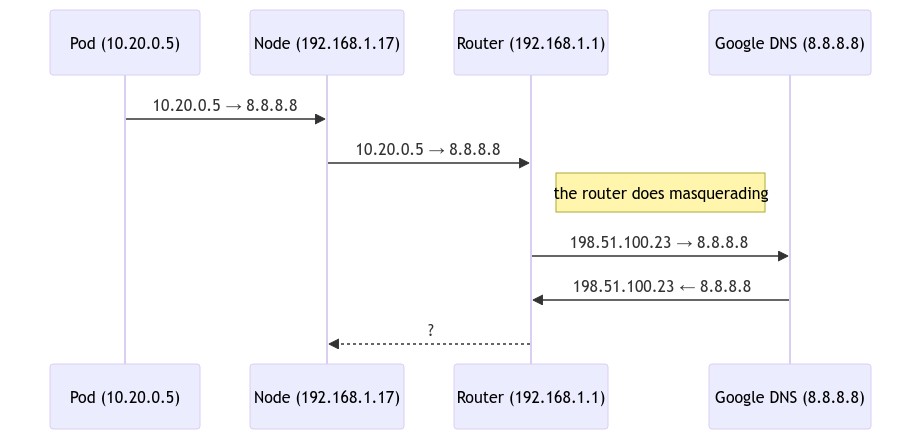
The router doesn’t know where to set traffic for 10.20.0.0/24, so everything breaks down. In a proper setup we’d use cilium BGP here to announce the pod subnets to the router, but the BGP support is somewhat broken for a dual-stack setup and Mikrotik really hates the announcements cilium’s gobgp does. In my case, given it’s a single-node cluster, I just hardcoded the reverse route:
/ip route
add check-gateway=ping comment="TEMP horse pod" disabled=no distance=1 \
dst-address=10.20.0.0/16 gateway=192.168.1.17 pref-src="" \
routing-table=main scope=30 suppress-hw-offload=no target-scope=10
Note how the dst-address covers both cilium pools. We don’t care which pool we need to reach, both are routable via 192.168.1.17.
With this setup, the router now knows that the return traffic should go to 192.168.1.17, and it will reach the pod once the CNI sees it.
For the VPN case the flow is only slightly different:
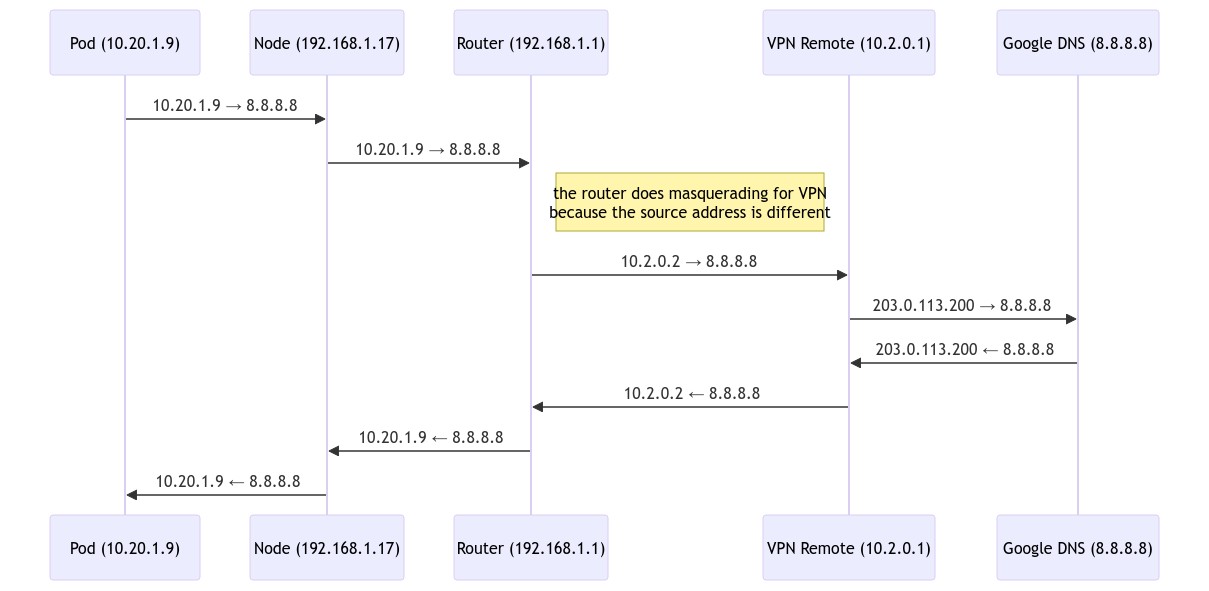
In here, the mangle rule triggers and changes the default gateway, that causes RouterOS to masquerade the traffic from 10.2.0.2. it flows into the VPN instead, and Google Pubnlic DNS sees the request from a different IP. The way back is exactly the same, though.
The IPv6 case for the default pool is very similar, apart from no masquerading happening at all. As pods have the public addresses already, it’s only the matter of having the return routes set:
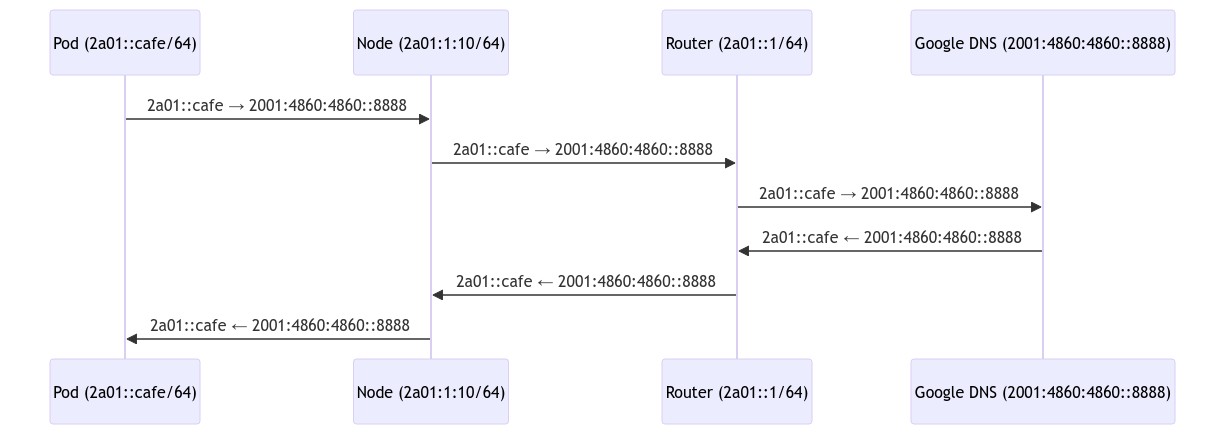
The traffic flows directly from the pod to google public DNS (yes, the remote will see the unique pod IP address here), and back. No address mangling, no complex rules, IPv6 is awesome.
Offloading the masquerading decisions from your CNI to the routers allows you to be more flexible with how the traffic navigates the tricky network topology. Paired with cilium multi-pool it allows your routers some awareness on what kind of payload the traffic originates from, too.